

Fabasoft ist unter anderem durch das Engagement in den Arbeitsgruppen CSPCert der EU und Securing Artificial Intelligence der ETSI sowie durch das europäische Projekt MEDINA seit Längerem im Bereich Cybersecurity, Datenschutz, Compliance und deren gemeinsamer Verknüpfung mit Komponenten Künstlicher Intelligenz (KI) aktiv involviert.
Im Zusammenhang mit den mittlerweile sehr komplexen und großen Datenmengen im Compliance-Umfeld, beispielsweise auch beim neuen EU Cloud Code of Conduct oder dem entstehenden European Cybersecurity Standard (EUCS), kristallisieren sich interessante Fragestellungen zum Thema automatisierte, unterstützende Analyse und Aufbereitung der Daten mithilfe von Künstlicher Intelligenz heraus. Natural Language Processing (NLP), ein Teilbereich der KI-Forschung, welcher sich mit dem Verstehen von natürlicher Sprache beschäftigt, stellt dabei einen wesentlichen Aspekt dar.
Ansätze zur Extraktion compliance-relevanter Informationen
Die Grundüberlegung ist, dass entsprechend entworfene und trainierte Systeme wichtige Informationen aus Daten und Dokumenten strukturiert aufbereiten und so mehrere Unterstützungsoptionen für Experten, Datenschutzbeauftragte und CISOs bieten:
- Abweichungsanalyse von Inhalten auf Basis von „Cosine Similarity“ (mathematische Methode zur Bestimmung von Ähnlichkeiten, u. a. in Dokumenten)
- Auffinden relevanter Passagen und deren Zusammenhänge durch semantische Klassifizierer (Zuordnung von Textpassagen zu Beweiskategorien)
- Darstellung von Executive Summarys umfangreicher Textdaten durch „Information Mining“ (Datenauswertung)
Langfristig relevanter sind aber Fragen rund um die automatische Compliance-Auswertung sprachlicher und graphischer Inhalte mit Hilfe von Machine Learning-Algorithmen.
Hierzu verfolgt Fabasoft die nachfolgend näher erläuterte Idee, die es in einem gemeinsamen Forschungsprojekt mit Partnern umzusetzen gilt.
State of the Art
Derzeit gibt es keine automatische Extraktion von Beweisen aus unstrukturiertem Text für den Einsatz in „Continuous Certification Systems“ (CCS). Für Auditoren bedeutet das manuelle Begutachten von Dokumenten und Screenshots der Cloud Service Provider (CSP) einen hohen Aufwand, da jeder CSP seine implementierten Sicherheitskontrollen und Prozesse unterschiedlich beschreibt.
Innovation: Automatisierte Beweisextraktion
Der größte Vorteil einer automatisierten Beweisextraktion für CCS ist die Zeitersparnis bei der Auditierung und Zertifizierung für ein Sicherheitssystem. Derzeit kann das in MEDINA geplante System nur strukturierte Evidenzen verarbeiten. Mit „Automatic Evidence Extraction“ (AEE), der Automatischen Beweisextraktion, entfällt die mühsame manuelle Prüfung von Änderungen zwischen Audits in Zukunft weitgehend.
Die Integration dieser Rohnachweise in eine kontinuierliche Zertifizierungspipeline geht damit einher.
Projektidee
Der Ansatzpunkt von Fabasoft und ihren Partnern ist die automatische Extraktion und Analyse von Nachweisen aus Dokumenten, die ein Auditor zur automatischen Bewertung von Sicherheitskontrollanforderungen (Security Control Requirements) für eine „Security Scheme Certification“ (Security-Zertifizierung) heranzieht.
Derartige Analysen sind bei kontinuierlichen Zertifizierungssystemen (CCS) für Cloud-Dienstleister verwendbar (Details dazu finden sich in meinen Blogartikeln: Cybersecurity: Echtzeitdaten zur Zertifizierung von Cloud-Diensten, MEDINA und EU Cybersecurity).
Anwendungsfall: Automatische Beweisextraktion aus natürlichsprachlichen Texten
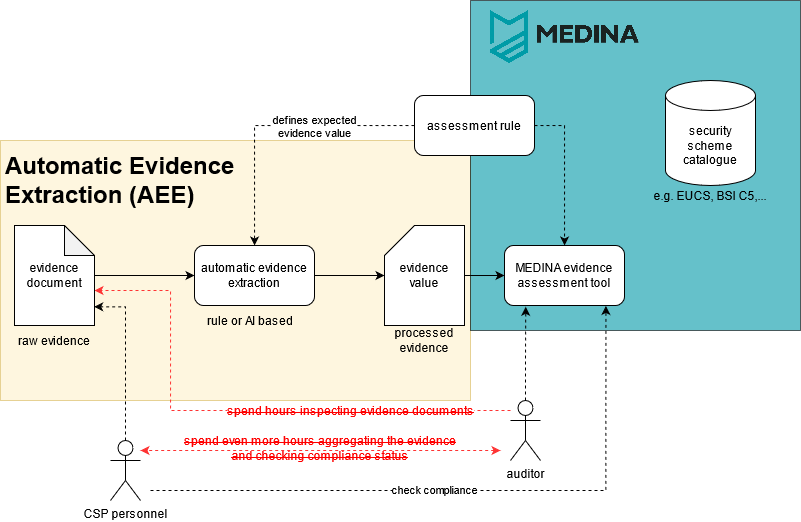
Abbildung: Automatische Beweisextraktion als Ergänzung zu MEDINA.
Obige Abbildung zeigt die mögliche Ergänzung des MEDINA-Projektes durch die Automatische Beweisextraktion (AEE). Der gelbe Bereich deckt die Kernidee der AEE aus Dokumenten ab. Die hier enthaltenen Evidenz-Dokumente (textuelle Beschreibungen, Logdateien oder Prozessdiagramme) entsprechen den von Auditoren für Zertifizierungen akzeptierten Beweismitteln aus der Praxis. Das Ziel ist, Evidenzwerte zur Bewertung der Compliance, beispielsweise mit dem European Cybersecurity Standard, automatisiert aus Dokumenten zu extrahieren. Da Evidenzdaten meist in Form von natürlicher Sprache (Natural Language) vorliegen, fokussiert die Idee darauf, natürlichsprachlichen Text in Evidenzwerte zu übersetzen, die wiederrum künftig als Input für ein Continuous Certification System (z. B. das MEDINA-Evidenzbewertungstool) dienen. Eine Weiterverarbeitung von Evidenzen, deren Inhalt bereits für die Verwendung in CCS passend strukturiert ist, erfolgt in der AAE nicht.
Die Automatic Evidence Extraction zielt indirekt darauf ab, die Sicherheit von Cloud-Systemen zu erhöhen, da sie die notwendigen Zwischenschritte zur Aufrechterhaltung und Kontrolle von Sicherheitsmaßnahmen bereitstellt. Eine kontinuierlich überwachte und zertifizierte Sicherheit der CSP stärkt schlussendlich auch das Vertrauen der Endanwender in Cloud-Services.
Das Fabasoft Research Alliances Team bringt die langjährige Erfahrung von Fabasoft im Umgang mit Evidenzdaten bei unzähligen Audits wie dem EU Cloud Code of Conduct Level 3-Zertifikat in das Projekt ein. Diese umfasst Know-how über „Information Retrieval“, grundlegende regelbasierte Informationsextraktion und angewandte maschinelle Lernkonzepte mit NLP.
Sie möchten mehr zu NLP erfahren? Lesen Sie meinen Blogartikel Natural Language Processing – KI die uns versteht?


