

Fabasoft has been heavily invested in the fields of cybersecurity, data privacy, compliance, and their shared connection with components of artificial intelligence (AI) for some time, in part through the company’s involvement in the EU’s CSPCert and ETSI’s Securing Artificial Intelligence working groups, as well as through its participation in the European MEDINA project.
The now highly complex and immense data volumes in the compliance environment, including those in the new EU Cloud Code of Conduct and the emerging European Cybersecurity Standard (EUCS), are giving rise to a number of fascinating new questions surrounding automated, supportive data analysis and processing based on artificial intelligence. Natural language processing (NLP), a subfield of AI research that deals with understanding natural language, is a key aspect in this context.
Approaches to extracting compliance-related information
The basic premise is to have well-designed and properly trained systems that process important information derived from data and documents in a structured format, offering multiple support options for experts, data privacy officers, and CISOs, such as:
- Analyzing deviations in content using cosine similarity (a mathematical method for determining similarities, such as those between documents)
- Finding relevant passages and their connections and correlations using semantic classifiers (assigning text passages to categories of proof)
- Presenting executive summaries derived from high-volume text data using information mining (data analysis)
In the long term, however, the issues that hold greater relevance are those revolving around using machine learning algorithms to automatically evaluate the compliance of linguistic and graphical content.
In this regard, Fabasoft is pursuing an idea that is outlined more fully as follows – one that will be realized in a joint research project in cooperation with partners.
State of the art
Currently, there is no way to automatically extract proof from unstructured text for use in continuous certification systems (CCS). For auditors, manually reviewing the documents and screenshots from cloud service providers (CSPs) requires considerable effort since every CSP has its own way of implementing security controls.
Breakthrough: Automatic evidence extraction
The number one benefit of automatic evidence extraction for CCS is the sheer amount of time it saves when it comes to auditing and obtaining certification for a security system. At present, the system proposed in MEDINA can only process structured evidence. Thanks to automatic evidence extraction (AEE), the painstaking process of manually reviewing changes between audits will be largely eliminated in the future.
Integrating this raw evidence into a continuous certification pipeline goes hand-in-hand with this.
Project idea
The approach taken by Fabasoft and its partners involves automatically extracting and analyzing evidence from documents that an auditor would use to automatically assess security control requirements for obtaining a security scheme certification.
These kinds of analyses can also be used with continuous certification systems (CCS) for cloud service providers (for details, see my blog articles “Cybersecurity: Certifying cloud services with real-time data” and “MEDINA and EU cybersecurity”).
Use case: Automatic evidence extraction from natural language texts
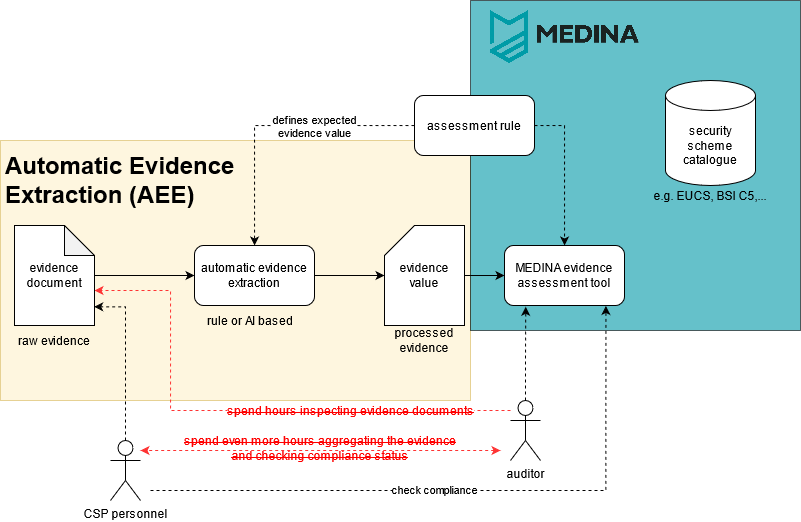
Figure: Automatic evidence extraction as a complement to MEDINA
The figure above shows how automatic evidence extraction (AEE) could complement the MEDINA project. The yellow section captures the core idea of the AEE from documents. The documentary evidence (textual descriptions or log files) included here correspond to real-world evidence accepted by auditors for certification. The objective is to automatically extract evidence values from documents to assess compliance with security standards such as the European Cybersecurity Standard. Since evidence-based data typically exists in the form of natural language, the project focuses on translating natural language text into evidence values, which in turn will serve as input for a continuous certification system (like the MEDINA evidence assessment tool) in the future. In AAE, there is no further processing of evidence for which the content is already suitably structured for use in CCS.
Indirectly, automatic evidence extraction aims to enhance security for cloud systems by taking the intermediate steps needed to maintain and monitor security measures. And ultimately, continuously monitored and certified CSP security also bolsters end-user confidence in cloud services.
By participating in the project, the Fabasoft Research Alliances team will have the chance to incorporate Fabasoft’s long-standing experience in managing evidence-based data, as demonstrated in innumerable audits including the EU Cloud Code of Conduct Level 3 certificate. This includes expertise in information retrieval, basic rule-based information extraction, as well as applied machine learning concepts based on NLP.
Would you like to learn more about NLP? Have a look at my blog article Natural language processing – AI that understands us?


